- Проблемы современного машинного обучения
- The State of AI Report 2021
- Papers With Code: самые последние достижения в области Машинного Обучения
- Journal of Machine Learning Research (JMLR)
- arXiv.org --- Computer Vision and Pattern Recognition
- DAWNBench --- An End-to-End Deep Learning Benchmark and Competition.
Генеративно-состязательные нейросети (GAN)
- PFA-GAN: Progressive Face Aging with Generative Adversarial Network
-
stylegan2-distillation.
Evgeny Kashin. Код для запуска в Google Colab:
!git clone https://github.com/EvgenyKashin/stylegan2-distillation.git %ls %cd stylegan2-distillation/
- Simple Pytorch StyleGAN2-Distillation Implementation
- IMDB-WIKI – 500k+ face images with age and gender labels
- Simple StyleGan2 for Pytorch
-
Создаем новый ноутбук. В «Runtime» => «Change runtime type» выбираем «GPU».
!pip install scipy==1.3.3 requests==2.22.0 Pillow==6.2.1 !pip install tensorflow-gpu==1.15.3 !git clone https://github.com/NVlabs/stylegan2.git %ls %cd stylegan2/ !python run_generator.py generate-images --network=gdrive:networks/stylegan2-ffhq-config-f.pkl \ --seeds=6600-6625 --truncation-psi=0.5
- Созданные фотографии можно найти в папке «results». При выборе параметров «--seeds=6600-6625 --truncation-psi=0.5» создаются фотографии, приведенные в Figure 12 оригинальной статьи. Если выбрать параметры «--seeds=66,230,389,1518 --truncation-psi=1.0», то будут созданы фотографии, представленные в Figure 11.
- Noise Mapping Network, Z => W, преобразует noise vector Z (512×1) в промежуточный noise vector W (512×1) через простейшую нейросеть, состоящую из восьми полносвязанных слоев.
- Truncation trick in W. Если мы посмотрим на распределение обучающих данных (training data), то становится ясно, что области с низкой плотностью (areas of low density) представлены плохо и, следовательно, у Генератора нет достаточных данных для хорошего обучения в этих областях, т.е. Генератор не способен их изучить и создать качественные изображения. Это известная проблема для всех методов генеративного моделирования. Однако известно, что отрисовка скрытых векторов из усеченного (truncated) или иным образом сокращенного пространства выборки (sampling space) имеет тенденцию улучшать среднее качество изображения, хотя некоторые вариации теряются. Truncation Trick (Трюк с усечением) - это скрытая процедура выборки для генеративных состязательных сетей, при которой производится выборка из усеченного нормального распределения и значения, выходящие за пределы диапазона, переформируются заново, чтобы попасть в этот диапазон.
- Random Noise Injection [A] осуществляется перед каждым блоком Adaptive Instance Normalization (AdaIN). Цель - передать изученную информацию о стиле из промежуточного вектора шума (W) на сгенерированное изображение в целях усиления контроля за изображением.
- Adaptive Instance Normalization (AdaIN). Учитывая изображение (𝑥𝑖) и промежуточный вектор шума W, AdaIN берет нормализацию экземпляра изображения, умножает ее на масштаб стиля
(𝑦𝑠) и добавляет смещение стиля (𝑦𝑏).

- Progressive Growing. Этот компонент помогает StyleGAN создавать изображения с высоким разрешением, постепенно удваивая размер изображения до желаемого размера.
- Метрика Inception Score (IS) использует «нейросеть Inception-v3», обученную на ImageNet, для классификации сгенерированных изображений, и вычисляет вероятность принадлежности изображений каждому из 1000 классов. Вероятности суммируются и образуют итоговую оценку IS со значениями от 1 до N, где N – количество классов.
-
Fréchet Inception Distance (FID) считается более продвинутой метрикой по сравнению с Inception Score и тоже использует Inception-v3. FID исключает последний полносвязный слой (fully connected layer) и основана на сравнении
«2048-dimensional
activations of the Inception-v3 pool3 layer» сгенерированных и реальных изображений, т.е. сравнивает специфические признаки изображений (Feature Extraction), полученные из значений функций активации предпоследнего слоя Inception-v3. Для
реальных и
сгенерированных изображений рассчитывается многомерное нормальное распределение на основе среднего значения и ковариации активаций предпоследнего слоя. Значение FID равно расстоянию между двумя распределениями. Чем ниже значение FID, тем
более
высокого качества изображение.

-
Improved Precision (точность) and Recall (полнота) Metric for Assessing Generative Models. Precision - доля объектов,
названных
классификатором положительными и при этом действительно являющимися положительными, а для GAN - доля сгенерированных изображений, которые являются реалистичными. Recall - доля объектов положительного класса из всех объектов положительного
класса,
которые нашел алгоритм; для GAN - доля множества обучающих данных, покрытых генератором.
Pr - распределение реальных изображений (синее). Pg - распределение сгенерированных изображений (красное). Precision - вероятность того, что случайное изображение в Pg подпадает в область Pr. Recall - вероятность того, что случайное изображение в Pr подпадает в область Pg.

Face Aging
Список улучшений в StyleGAN2 от Nvidia:

Простейшая инструкция по запуску StyleGAN2 на Google Colab
Компоненты нейросети StyleGAN от Nvidia:

Метрики оценки качества генеративно-состязательных нейросетей (GAN) «measuring the quality of generated image samples»:
Курс CS231n "Сверточные нейронные сети для распознавания образов"
- Курс CS231n: "Convolutional Neural Networks for Visual Recognition" (примеры решений представлены в обратном порядке от прохождения в курсе). Assignments 1 и 2 для Spring 2019, Assignment 3 для Spring 2020:
-
Генеративная состязательная сеть (Generative Adversarial Network, GAN) основана на идее использования модели генератора (Generator model) для создания поддельных примеров и модели дискриминатора (Discrimator model), которая пытается
определить, является ли полученное изображение поддельным (то есть от Генератора) или реальным образцом. Простейшие GANы работают на полносвязных сетях (fully connected networks).
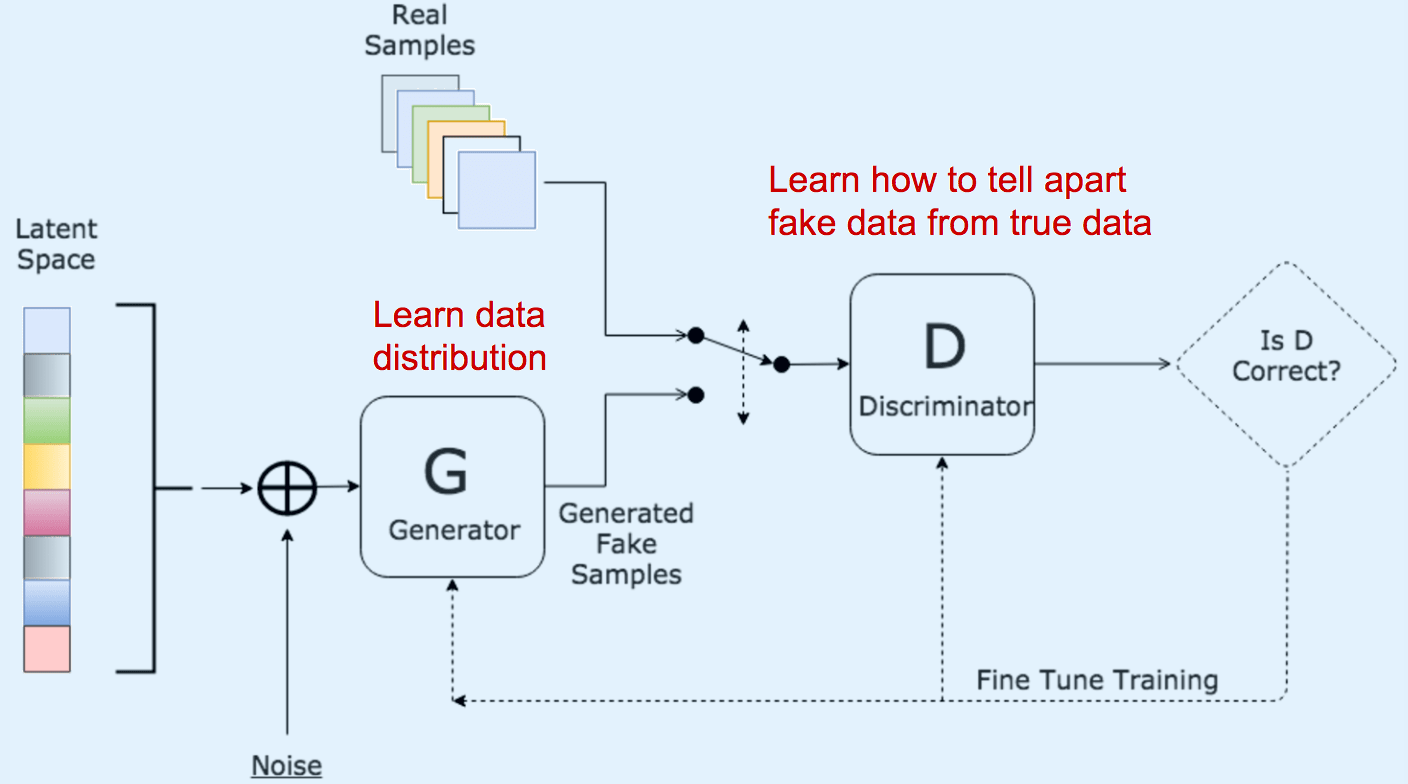
-- GAN с глубокой сверткой (Deep Convolution GAN, DCGAN) работает на базе глубоких сверточных сетей (Deep Convolutional networks), которые находят области корреляции внутри изображения, то есть они ищут пространственные корреляции. Это означает, что DCGAN, больше подходит для работы с изображениями и видео, тогда как общая идея GAN может быть применена к более широким областям.
-- Wasserstein GAN with Gradient Penalty. WGAN-GP не предназначен для улучшения общей производительности GAN, но повышает стабильность и позволяет избежать Mode Collapse. Минусом WGAN-GP за возможность более стабильного обучения по сравнению с обычным DCGAN, является существенно более медленная работа, потому что Gradient Penalty требует, чтобы вычислялся градиент градиента. Здесь подробное объяснение особенностей Wasserstein GAN.
- Автоматическая аннотация изображений (Image Captioning): 1, 2, 3, 4, 5.
- Рекуррентные нейронные сети: 1, 2, 3.
- Решение Image Captioning with LSTMs LSTM_Captioning.ipynb.
- Решение Image Captioning with Vanilla RNNs RNN_Captioning.ipynb.
- Упрощенная версия ResNet c учетом ограничений в задании (PyTorch_ResNet.ipynb). Достигнута точность - 73,99%.
- На базе очень простого решения (PyTorch_2.ipynb) достигнута точность - 78,20%.
-
Решение (PyTorch.ipynb) на базе модели
AlexNet c учетом ограничений задания. Достигнута точность - 74,38%.:
-- Загрузка датасета CIFAR-10 с помощью PyTorch.
-- Трехслойная сверточная нейронная сеть на "голом" PyTorch.
-- Пояснения по использованию PyTorch Sequential API (контейнерный модуль nn.Sequential), который не так гибок, как nn.Module, потому что нельзя указать более сложную топологию, чем стек feed-forward, но это то, что как раз нужно для нашего упражнения.
-- Перевод статьи курса Convolutional Neural Networks (CNNs / ConvNets), где кратко дан обзор LeNet, AlexNet, ZF Net, GoogLeNet, VGGNet и ResNet.
-- Руководство по арифметике свертки для глубокого обучения (A guide to convolution arithmetic for deeplearning).
-- Интуитивное понимание 1D, 2D и 3D сверток в сверточных нейронных сетях.
-- Класс torch.nn.Conv2d().
-- Умножение матриц - torch.mm(). - Обзор методов нормализации в глубоком обучении. Group Normalization на Python в ConvolutionalNetworks.ipynb.
- Трехслойная сверточная нейронная сеть (cnn.py) со следующей архитектурой: conv - relu - 2x2 max pool - affine - relu - affine - softmax.
- Ускорение (fast_layers.py) Python-кода с помощью Cython при прохождении "the forward pass" и "the backward pass" в сверточных слоях. Очень хорошее объяснение методов прямого прохождения ("the forward pass") и обратного распространения ошибки в свёрточной нейронной сети: 1, 2 и 3.
- Преобразование изображения в оттенки серового (Grayscale) и выделение границ (Edge detection) с помощью прямого прохождения (forward pass) в свёрточной нейронной сети.
- Визуализация в браузере процесса обучения свёрточной нейронной сети на датасете CIFAR-10.
-
Полностью связанная нейронная сеть с произвольным количеством скрытых слоев, нелинейностями ReLU и функцией потерь Softmax
(FullyConnectedNets.ipynb).
Достигнута точность 59,5%. Подбор параметров в
FullyConnectedNets_Best.ipynb.
Архитектура сети (fc_net.py): {affine - [batch/layer norm] - relu - [dropout]} x (L - 1) - affine - softmax; где
-- L - количество слоев;
-- affine - слой в котором все содержащиеся узлы (nodes) соединяются со всеми узлами последующего cлоя;
-- dropout в версии Inverted Dropout (Инвертированный Dropout). С помощью Dropout можно менять силу регуляризации, просто варьируя значение параметра p. Подробно в Dropout.ipynb.
-- batch normalization. Пояснения: 1, 2, 3. Подробно в BatchNormalization.ipynb.
-- layer normalization
Возможность выбора (реализовано в optim.py) между:
-- Vanilla stochastic gradient descent
-- Stochastic gradient descent with momentum
-- RMSProp update rule
-- Adam update rule. Этот алгоритм градиентной оптимизации стохастических целевых функций первого порядка, основанный на адаптивных оценках моментов низкого порядка, рекомендуется использовать по умолчанию. -
Пример (features.ipynb)
улучшения производительности классификации изображений при обучении линейных классификаторов и двухслойной нейронной сети посредством предварительного преобразования необработанных пикселей в:
-- гистограмму направленных градиентов на основе работы Histograms of Oriented Gradients for Human Detection и
-- цветовую гистограмму, используя канал оттенка (Hue) в цветовом пространстве HSV.
В результате мы формируем окончательный входящий вектор признаков (features) для каждого изображения, объединяя векторы признаков HOG и цветовой гистограммы, которые дополняют друг дуга: HOG захватывает текстуру изображения, игнорируя информацию о цвете, а цветовая гистограмма представляет цвет входного изображения, игнорируя текстуру. Достигнута точность - 58,8%. - Пример классификации изображений (two_layer_net.ipynb) в CIFAR-10 с помощью простейшей двухслойной нейронной сети, натренированной с помощью stochastic gradient descent (SGD), используя Softmax classifiers. Пример перехода от Softmax Linear Classifier к двухслойной нейронной сети здесь. Три пояснения по вычислению производной Softmax loss function для обратного распространения ошибки (backpropagation, вычисления градиента): 1, 2, 3. После настройки гиперпараметров достигнута точность - 54%.
- Пример классификации изображений (softmax.ipynb) в CIFAR-10 с помощью функции Softmax для минимизации перекрестной энтропии. Цель примера - показать различия между двумя алгоритмами классификации: SVM и Softmax. Достигнута точность - 34%, что даже немного меньше, чем при использовании SVM. Cуть различий в том, что для данного изображения классификатор SVM может дать оценки [12,5 0,6 -23,0] для целевой переменной «кошка», «собака» и «корабль». Классификатор Softmax может вместо этого вычислить вероятности этих трех целевых переменных как [0,9 0,09 0,01]. Другими словами, классификатор SVM успешно отделит автомобили от грузовиков, но добавление на изображение лягушек не будет иметь большого значения для границ принятия решения, поскольку лягушки обычно будут так далеко от автомобилей, что SVM просто проигнорирует их влияние на модель. А вот классификатор Softmax пересчитает и включит влияние лягушек. Соответственно, решение какой классификатор использовать, зависит от того, хотите ли вы простой классификатор, который отделяет автомобили от всего остального - SVM, или модель, которая дает вероятность для каждого класса - Softmax.
- Визуализация функции потерь (loss function) для различных алгоритмов мультиклассовой классификации Методом Опорных Векторов - Multiclass SVM (Weston Watkins 1999, One vs All, Structured SVM), а также Softmax.
- Классификация изображений (svm.ipynb) в датасете CIFAR-10 c помощью линейного SVM классификатора (Linear SVM Classifier), использующего метод Стохастический градиентный спуск (Stochastic gradient descent) для оптимизации функции потерь, Multiclass Support Vector Machine (SVM) loss или Hinge loss. Достигнута точность 37,6%.
- Визуализация алгоритма К-ближайших соседей (k-Nearest Neighbor, kNN)
- Классификация изображений (knn.ipynb) методом К-ближайших соседей (k-Nearest Neighbor, kNN) из датасета CIFAR-10. Достигнута точность - 28,2%.
- Официальные материалы. Общие заметки по курсу. Midterm 2019 + слайды по Midterm 2020. Статьи по теме: 1, 2, 3, 4, 5, 6.
Assignment 3. Generative Adversarial Networks. Image Captioning with Vanilla RNNs and with LSTMs.
Assignment 2. Fully-Connected Nets, Batch Normalization, Dropout, Convolutional Nets.
Assignment 1. Image Classification on CIFAR-10: kNN, SVM, Softmax, Neural Network.
Архитектуры нейронных сетей
- Перевод статьи "Зоопарк архитектур нейронных сетей".
- Оригинальная статья The Neural Network ZooОригинальная статья The Neural Network Zoo.